After months of using claude-mem, my memory store had 8,785 observations across 13 projects. I'd never actually seen any of them surface in a Claude Code session unless I explicitly asked. I had a perfect memory store and zero working memory.
That was the realization that broke the framing. My AI memory problem wasn't a storage problem. It was a working-memory problem — and nothing on the shelf was solving it. So I built SuperBrain.
TL;DR
SuperBrain is an open-source Claude Code plugin that captures every session into a plain Obsidian markdown vault — and automatically surfaces the relevant prior context at the start of your next session. No MCP search. No explicit recall command. Plain files you own, on your machine, no API key. The architectural bet: storage is solved; what's missing is automatic, context-aware injection at the right moment.
Why I built it
Qodo's 2025 State of AI Code Quality survey (n=609) found 65% of developers say AI tools miss relevant context during real work, and "improved contextual understanding" was the #1 requested fix at 26% of all votes. But "context" gets used loosely. There's within-session context loss — largely solved in 2026 by Cursor's @-mentions and Claude Code's file-graph traversal. And there's between-session context loss — Claude has no memory of the trade-off you litigated last week. That half is what's actually broken.
The existing memory tools all attack it the same way: capture, compress, store.
| Tool | Stars | Storage | Retrieval |
|---|---|---|---|
claude-mem | 78k+ | SQLite + compressed observations | MCP search (v4 retreated from auto-inject after v3 caused context pollution) |
mem0 | 48k+ | Vector store + LLM extraction | Auto-recall in agent loops; not IDE sessions |
basic-memory | 3.1k | Plain markdown + SQLite | Explicit search_notes / build_context MCP calls |
mcp-memory-service | 1.9k | ChromaDB / SQLite-vec | Explicit MCP query |
The retrieval row is uniformly the same: an MCP tool the agent has to remember to call. claude-mem's own architecture docs admit it: v3 tried to auto-inject everything at session start, hit "context pollution (thousands of tokens of irrelevant data)," and v4 retreated to a 800-token index — the actual memories now require an explicit search.
Anthropic confirms the gap in their docs. The first 200 lines of MEMORY.md auto-load; topic files like debugging.md "are not loaded at startup"; nested CLAUDE.md files "are not re-injected automatically" after /compact. The SessionStart hook exists precisely to fix this — but Anthropic ships the surface; the script is yours to write.
So I wrote one.
How SuperBrain actually works
SuperBrain composes a small set of parts — six mechanisms and one substrate — into a single invariant: your sessions become a journal you didn't write, and the relevant parts of that journal show up in Claude's context before you type your first prompt. Here's each piece.
Capture: hooks that never block
Every Claude Code session in 2026 emits events — tool calls, prompts, compactions, terminations. SuperBrain registers six hooks total: five on the capture side (PostToolUse, UserPromptSubmit, PreCompact, SessionEnd, Stop) that append a compact line to a per-session NDJSON log on every event, and a sixth — SessionStart — that handles recall (covered below). No LLM call on the capture path. The hot path can never rate-limit, stall, or disrupt your turn. Hooks always exit 0 no matter what — a crashing hook is impossible by construction.
The distillation work — the part that needs an LLM — runs as a detached child process on three checkpoint events (PreCompact, SessionEnd, Stop). It's lock-serialized, idempotent, and recoverable: a byte cursor in the NDJSON lets a killed or missed run pick up next session without dropping events.
Routing: turning raw events into structured notes
The detached sb-distill process reads the NDJSON, calls Claude (claude -p) to interpret the session, and writes into one of six scopes:
projects/— context that's specific to one repodecisions/— trade-offs you reasoned through, dated, with rationalelessons/— generalizable rules learned the hard way (e.g., "prefer X when Y")captures/— freeform thoughts and reference materialdaily/— what happened on a given day, with backlinks to the abovemeta/— your durable preferences (code style, conventions)
The router picks scope from the session content, not from the surface event type. A discussion about whether to use SQLite or DuckDB ends up in decisions/ regardless of whether it surfaced via a Bash tool call or a prompt edit. Every note carries provenance — which session distilled it, when, from which working directory.
Recall: project-scoped injection at SessionStart
This is the part that closes the loop. On every SessionStart, the hook reads the current directory, walks up to find the project root, and looks for a projects/<slug>.md anchor note. From there it runs a hybrid search — vector embeddings (all-MiniLM-L6-v2) fused with BM25 keyword matching via reciprocal rank fusion, then recency-weighted — across decisions/, lessons/, and captures/ tagged with the project. The top hits get compressed into a ~1,200-token recall block and injected into Claude's context before the first prompt.
You've already seen what that looks like, if you've read any well-instrumented Claude Code session this year:
SuperBrain recall (your vault may already answer this):
- [[decisions/2026-05-21-keep-cli-repo-public]] — Keep CLI repo public; filter OpenAPI spec upstream...
- [[lessons/2026-05-20-rebasing-feature-branch]] — Rebasing a feature branch from main needs no push-to-main caution...
- [[projects/superbrain]] — SuperBrain has two vault directories; only ~/.superbrain/vault is active...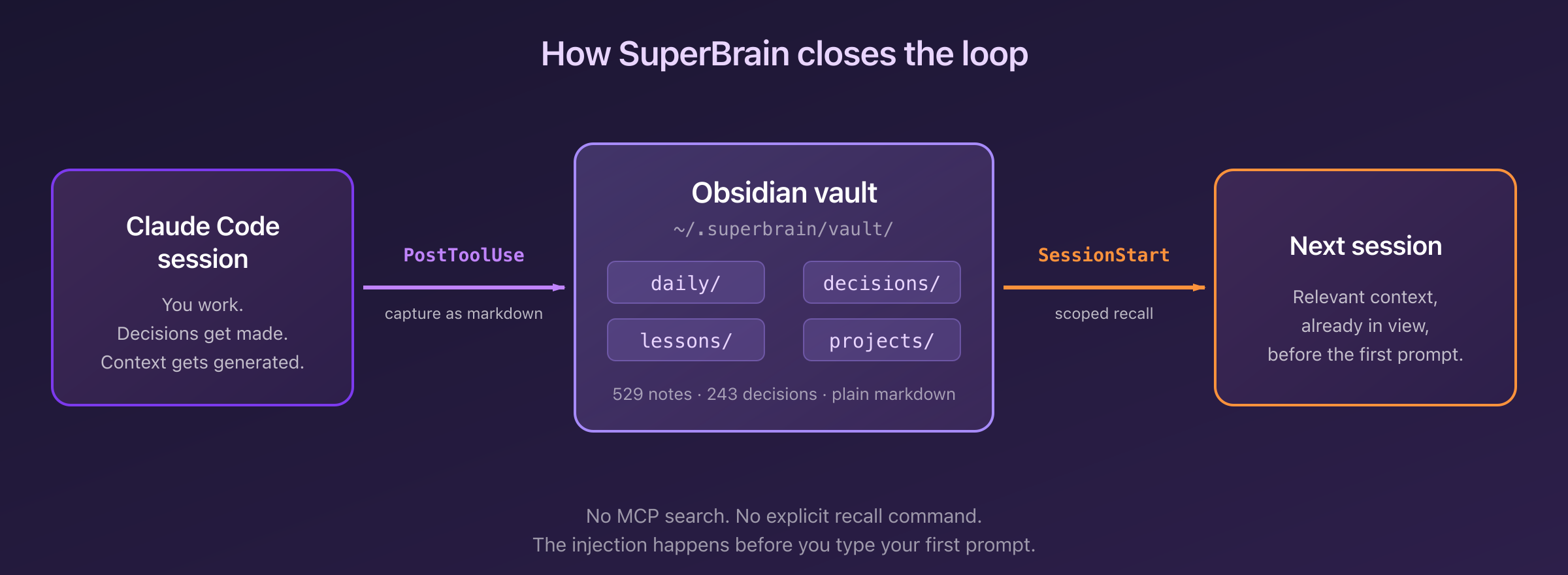
The token budget is the trick. claude-mem's v3 tried to inject everything and polluted the context. SuperBrain ships a précis, not a dump — small enough to never crowd out your prompt, specific enough to actually save you re-litigating.
Rollups: daily, weekly, monthly self-healing
A working memory needs more than per-session notes. SuperBrain emits time-based rollups: daily notes that link out to every session's distilled output, weekly rollups that summarize themes across days, monthly rollups for trend visibility. They're hash-gated and idempotent — if a session is killed mid-rollup, the next SessionStart picks up where it left off, no duplicates, no drift.
The daily note also doubles as a manual diary surface. Anything you append to today's daily/YYYY-MM-DD.md outside SuperBrain's structured zones is preserved verbatim — Obsidian users keep their freeform habits intact.
Manual capture: /superbrain:inject
Auto-capture covers the events SuperBrain can observe. But you also have thoughts the hooks don't see — a side observation while you're deep in another project, a meeting summary you want to keep, a quick reference link. /superbrain:inject takes a freeform blob, runs it through a small distiller, and routes it to the right scope automatically. Single short notes are preserved verbatim with provenance source: inject; longer multi-topic input gets split. Same vault, same router, same backlinks.
Migration: bringing your existing vault along
If you already have an Obsidian vault, /superbrain:migrate does a non-destructive import. The source vault stays read-only; SuperBrain's vault gets copies, categorized by Claude reading the source files at runtime. Your daily-note convention, your tagging system, your folder structure — preserved or remapped per your call during the migration conversation. No data lost, no surprise rewrites.
Storage: plain markdown all the way down
There is no SQLite for your notes. There is no vector DB for your notes. The search index at ~/.superbrain/index.db is incidental — derived, rebuildable from the files. Your notes are markdown files at ~/.superbrain/vault/, with YAML frontmatter and standard [[wikilinks]]. You can open them in Obsidian, grep them from your terminal, version them with git, or carry them between machines on a thumb drive. Deletes go to .trash/, never destructive. If SuperBrain disappears tomorrow, your vault is still your vault.
Install is two commands:
/plugin marketplace add m3talux/superbrain
/plugin install superbrainNo API key, no cloud account, no daemon, no scheduler, no per-project setup. The repo, full docs, and roadmap are at github.com/m3talux/superbrain.
The honest trade-off
The case against plain markdown is real. mem0's ECAI 2025 paper showed that a memory layer with LLM-driven consolidation (ADD/UPDATE/DELETE/NOOP operations on stored facts) keeps conversation memory at ~7K tokens. A naive dump blows out to ~600K — an 85× difference. Plain markdown dumps the consolidation problem on you.
SuperBrain's mitigation is that recall is project-scoped and recency-weighted, so the injection block stays small even as the vault grows. But yes — if you ran it for two years and never touched the vault, you'd accrue noise.
I accept that trade because it inverts the failure mode I care about. With claude-mem, the failure is silent — a relevant observation exists but never surfaces, and you never know it was there. With SuperBrain, the failure is visible — I can open the vault, see a relevant note, and notice it didn't make the recall block. One I can fix. The other I can't.
Key Takeaways
- AI memory tools have solved the storage half. The unsolved half is automatic, context-aware injection at the right moment — and it's where every retrieval-augmented system in 2026 still leaks value.
- SuperBrain's invariant: hooks capture, a detached process distills, the next
SessionStartinjects a project-scoped précis. No LLM on the hot path; no daemon; no API key; no cloud. - The capabilities compose: auto-capture, routing into six scopes, project-aware recall, daily / weekly / monthly rollups,
/superbrain:injectfor freeform thoughts, and/superbrain:migratefor non-destructive Obsidian vault imports. - Plain markdown has a real cost — the consolidation problem is yours — but it inverts the failure mode from silent to visible. Visible failures are fixable.
- SuperBrain is MIT and open-source. The architectural idea — automatic SessionStart injection scoped to the current project — is reusable in any Claude Code plugin you'd want to build.